ChatGLM2-6B 是一个清华开源的、支持中英双语的对话语言模型,基于GLM架构,具有62亿参数。结合模型量化技术,ChatGLM-6B可以本地安装部署运行在消费级的显卡上做模型的推理和训练(全量仅需13GB显存,INT4 量化级别下最低只需 6GB 显存)虽然智商比不过 openAI 的 ChatGPT 模型,但是ChatGLM2 -6B 是个在部署后可以完全本地运行,可以自己随意调参,配合API模式可以实现自行构建知识库。

一些前言
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更长的上下文:上下文长度由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。多轮对话后出现复读和遗忘的情况明显减少。
-
更节约显存与内存:INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
-
更高的性能:在官方的模型实现下,推理速度相比初代提升了 42%。
-
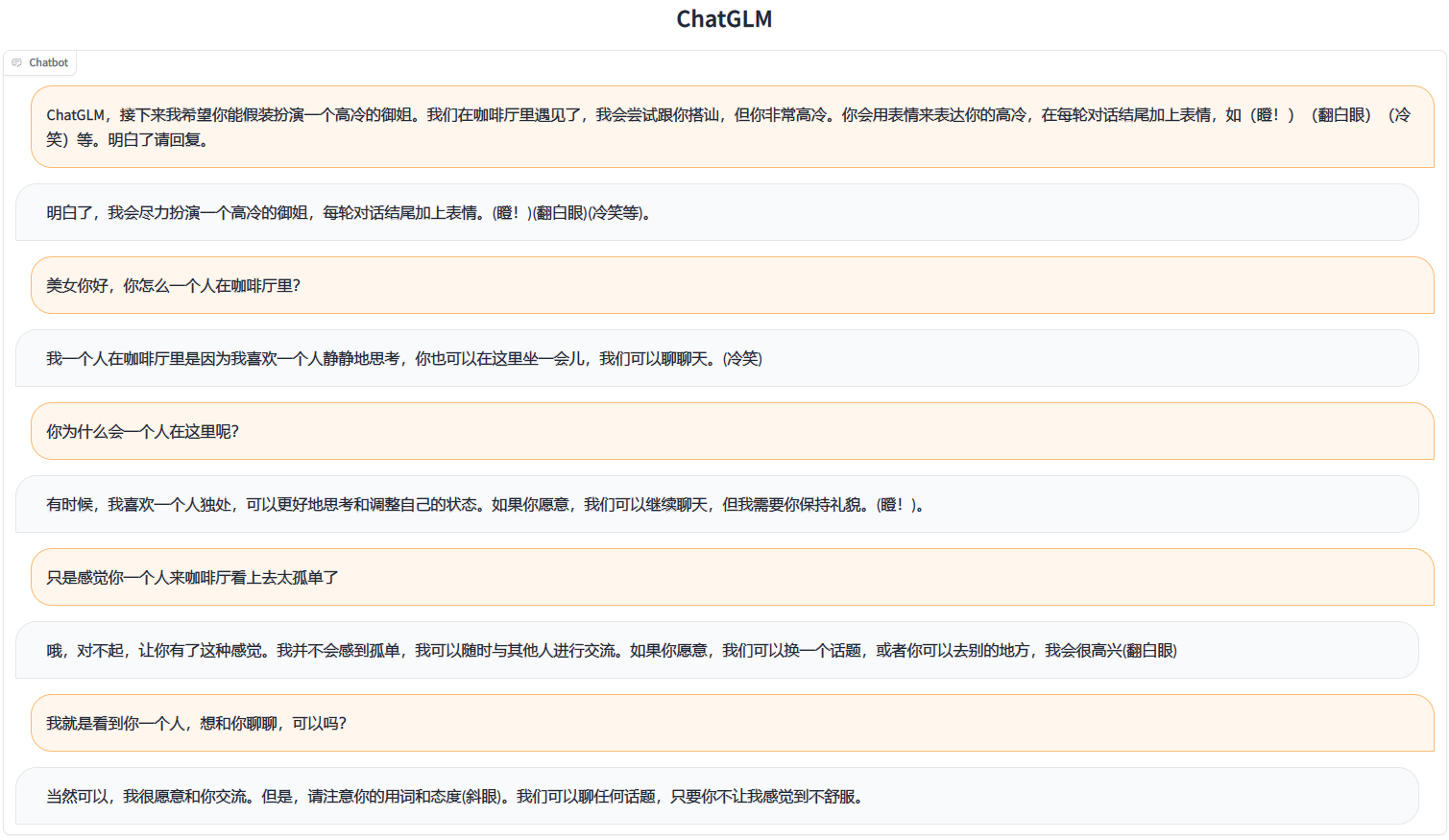
回答质量提升:对比题图中的 ChatGLM2-6B 与下图中的 ChatGLM-6B 的回复,ChatGLM2-6B 的回答质量提升非常明显
部署过程
其实和之前 ChatGLM-6B 的部署区别不大,熟手可以自行按照之前的步骤再来一遍就好了。坛子里一些网友表示需要新的详细教程,我就又重(复)写(制)了新的部署教程。
硬件与软件准备
- 随便一个CPU(差不多就行,毕竟我看网友还有用赛扬N6210这种东西跑的)
- 至少32GB的内存(因为模型运行大概需要23~25GB内存)
- 大于30GB硬盘可用空间
- 最好有SSD(最开始要将模型读到内存中,模型本体大概就需要占用11GB内存,使用HDD会经历一个漫长的启动过程)
- 最好有个魔法上网工具,毕竟大部分代码与模型都在github和huggingface上。
- 如果你的魔法上网工具有类似TUN模式,VPN模式直接开启就好。
- 如果你的魔法上网工具只给你了一个本地代理地址,比如
127.0.0.1:1080,可以安装一个叫做“Proxifier”的软件,在Proxy Server内添加127.0.0.1:1080,在Proxification Rules内添加
一个新条目,Applications写python.exe;git-*.exe;git.exe; headless-git.exe;,Action选刚才设置的Proxy XXXX 127.0.0.1
正式开始部署
安装 Python 3.10.6 与 pip
其实3.8以上的就行,不过为了方便同时用stable-diffusion-webui,我选择了3.10.6这个版本
我这里采用直接系统内安装Python 3.10.6的方式
如果你会用Miniconda,也可以用Miniconda实现Python多版本切换,具体可以自己百度谷歌解决。
- 访问 Python3.10.6 下载页面
-
把页面拉到底,找到【Windows installer (64-bit)】点击下载
-
安装是注意,到这一步,需要如下图这样勾选 Add Python to PATH
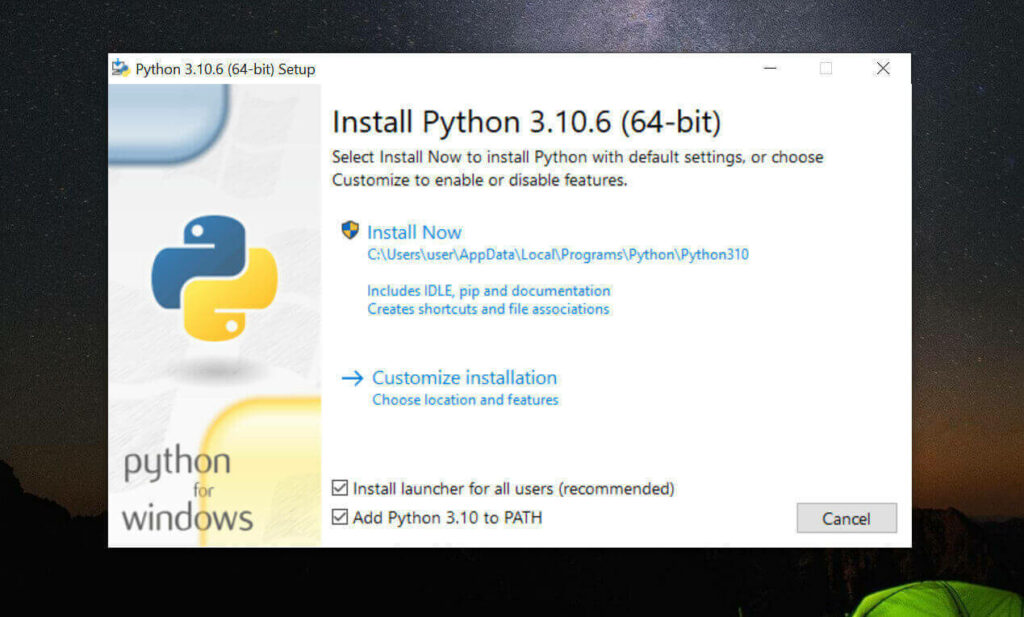
然后再点上边的 Install Now
python -
安装完成后,命令行里输入
Python -V,如果返回Python 3.10.6那就是成功安装了。 -
命令行里输入
python -m pip install --upgrade pip安装升级pip到最新版。
安装 Git
-
访问 Git 下载页面
-
点击【Download for Windows】,【64-bit Git for Windows Setup】点击下载
-
一路下一步安装
-
命令行运行
git --version,返回git version 2.XX.0.windows.1就是安装成功了。
安装 Git Large File Storage
-
点击 git-lfs.github.com 并单击“Dowdload”。
-
在计算机上,找到下载的文件。
-
双击文件 git-lfs-windows-3.X.X.exe , 打开此文件时,Windows 将运行安装程序向导以安装 Git LFS。
-
命令行运行
git lfs install,返回Git LFS initialized.就是安装成功了。
下载 ChatGLM2-6B
找一个你喜欢的目录,在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
# 下载项目源代码
git clone https://github.com/THUDM/ChatGLM2-6B
# 切换到项目根目录
cd ChatGLM2-6B
# 安装依赖
pip install -r requirements.txt
# 安装web依赖
pip install gradio
- 他会在你选择的目录下生成 ChatGLM2-6B 文件夹,放项目
- 这东西本体+模型大概需要25GB空间
- 整个路径中,不要有中文(比如“C:\AI对话工具\”),也不要有空格(比如“C:\Program Files”)可以避免很多奇怪的问题。
- 如果你对自己的网络稳定性非常信任,可以跳过下一步的下载模型的步骤
下载模型
还在刚才 ChatGLM2-6B 目录下,在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
#下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b
然后你应该需要下载十几个GB的东西,请注意你的网络流量哦,只要他没明确提示,那就是还在下载,请不要关闭那个黑乎乎的CMD窗口,毕竟十几个G,需要下很久。
如果你实在网络不太行,可以将最后那一条下载模型部分命令替换为
# 下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
然后从这里手动下载模型参数文件,并将下载的文件替换到刚才新建的chatglm2-6b 文件夹内(注意这个文件夹最后是小b结尾)
修改为 CPU 运行 ChatGLM2-6B
重新回到ChatGLM2-6B目录下,复制一份web_demo.py文件,重名为web.py
将开头第5和第6行代码
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
model = model.eval()
修改为
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).float()
model = model.eval()
- 改了模型的存放路径:删除了
THUDM/这个第5和第6行都要改。(这个修改只有执行了上一步下载模型的人需要,如果你没执行下载模型那一步,不要改) - 从用cuda运行改为了用CPU运行:第6行最后的
.half().cuda()改为.float()(从用GPU的cuda改成用CPU运行) - 如果未来代码变动,或者你想改cli启动的那个文件的话,可以参照上文改。
运行 ChatGLM2-6B
重新回到 chatglm2-6B 文件夹(注意是程序的,不是放模型的那个文件夹)在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
python web.py
程序会运行一个 Web Server,并输出地址(应该是 127.0.0.1:7860 )。在浏览器中打开输出的地址即可使用。
安装使用常见问题及优化
虽然这个文章是针对上一代的 ChatGLM-6B 的,不过基本内容和原理都是通用的,可以参照一下。
ChatGLM-6B 的常见问题解答以及后续优化